
背景
自从ChatGPT横空出世,大模型的发展日新月异,每个人都希望试一试大模型带来的魔力,但大模型对硬件的高要求让大家对这个新生事物的尝鲜屡屡碰壁,但没有什么难得到勤劳勇敢的程序员们的,最近赫然发现基于个人PC硬件环境搭载的大模型也已经成为可能,并在我在个人的mac上实现了本地化大模型的效果,这里把我本地化搭建的方案做个介绍。
技术方案
该本地化的方案涉及到3部分,对话大模型ChatGLM-6B,嵌入模型m3e-base,大模型知识库平台管理系统 FastGPT。
1、通过FastGPT进行私域知识的整理录入,然后由嵌入模型m3e-base做向量化处理。
2、当用户提问时,该问题经过向量化处理后,通用与私域知识的向量相似度比较以及一定的算法规则搜索出跟提问相关的知识。
3、相关知识再交给对话大模型ChatGLM-6B,进行大模型擅长的上下文理解,总结,推理,最后将答案输出。
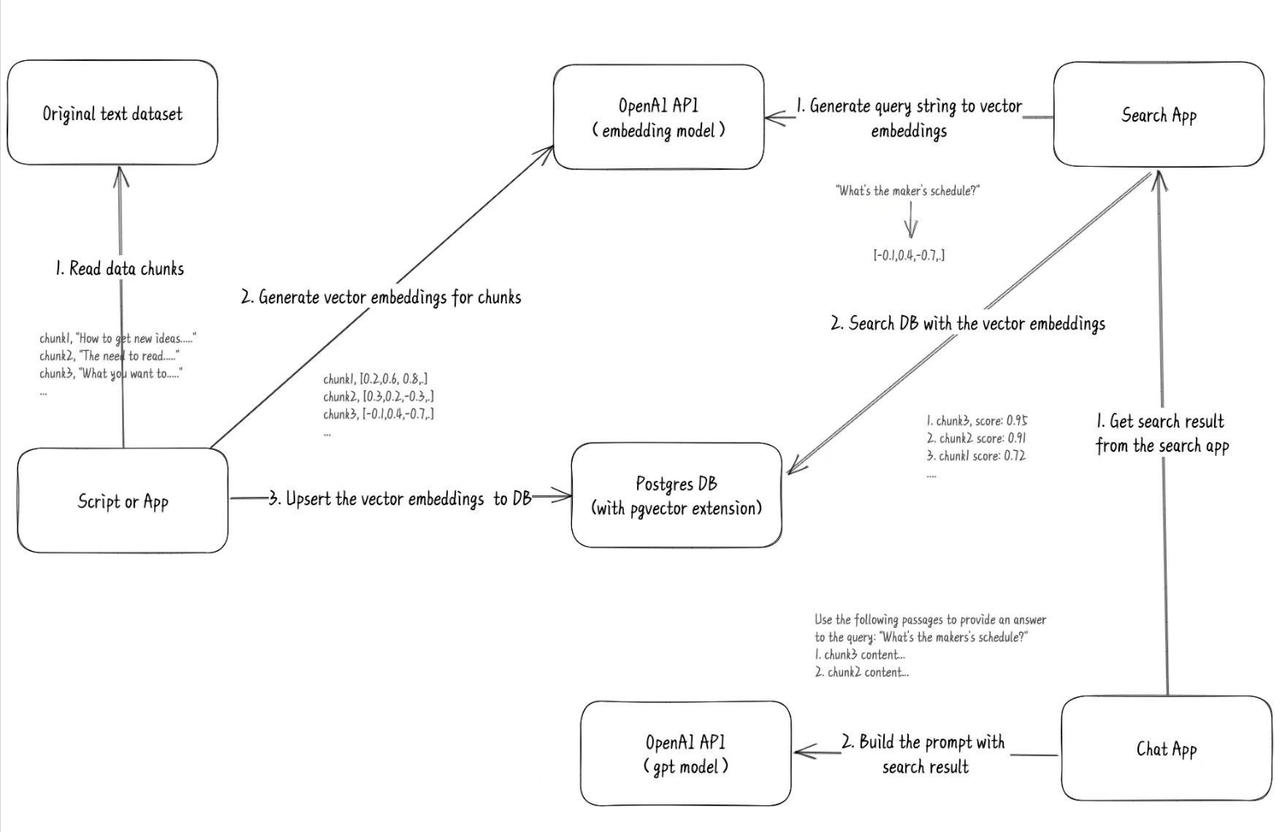
从 FastGPT 官网得知,这套开源系统基于以下几个基本概念进行知识库检索:
- 向量:将人类直观的语言(文字、图片、视频等)转成计算机可识别的语言(数组)。
- 向量相似度:两个向量之间可以进行计算,得到一个相似度,即代表:两个语言相似的程度。
- 语言大模型的一些特点:上下文理解、总结和推理。
结合上述 3 个概念,便有了 “向量搜索 + 大模型 = 知识库问答” 的公式。上图是 FastGPT V3 中知识库问答功能的完整逻辑。
搭建步骤
基础环境准备
python3.11 + pip3

准备大数据模型ChatGLM3-6B
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。
下载渠道
- HuggingFace: THUDM/chatglm3-6b
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b该模式的下载速率不是很稳定,如果实际使用下载效率不高可以用魔塔社区(ModelScope)的的方式下载
- ModelScope: ZhipuAI/chatglm3-6b
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git利用chatglm.cpp进行量化加速
大部分的LLM模型都是python实现的导致运行效率有限在很多个人mac上无法运行,后来有大神用c++重新实现了一遍,让chatglm3可以跑在mac乃至windows环境下。
Github Repo: https://github.com/li-plus/chatglm.cpp
git clone git@github.com:li-plus/chatglm.cpp.git
# cd到chatglm.cpp的根目录
cd xxxx
# 先初始化 git 仓库
git submodule update --init --recursive
# 构建可执行文件
cmake -B build
cmake --build build -j
# 安装 Python 依赖
pip3 install .安装完成之后就是对 ChatGLM3-6B 进行 8-bit 量化处理:
python3 ./chatglm_cpp/convert.py -i /xxxxx/chatglm3-6b -t q8_0 -o chatglm3-ggml-q8.bin上面的/xxxxx/chatglm3-6b要换成前面步骤里下载chatglm3-6b的路径,执行完成后会生成一个chatglm3-ggml-q8.bin文件。
如果执行不动的话,可以降低量化标准用4-bit,5-bit进行量化,但对应出来的大模型效果也会有所差别。具体参数可以参考https://github.com/li-plus/chatglm.cpp#readme

大模型问答效果验证
在得到chatglm3-ggml-q8.bin这个量化结果后,就可以跑出基本的命令行式的大模型问答
./build/bin/main -m chatglm3-ggml-q8.bin -i能够出现如上的命令行效果,本地基本就是具备大模型基本的推理总结能力了。
准备嵌入模型m3e-base
嵌入模型:嵌入模型是一种将单词、短语或文本映射到低维向量表示的模型。这些向量表示被称为嵌入向量(Embedding Vector)。嵌入模型的目的是在保留语义和语法信息的同时,将文本转换为计算机可以处理的向量形式。在自然语言处理中,嵌入模型常用于词嵌入(Word Embedding),如Word2Vec、GloVe等。这些模型可以将单词嵌入到连续向量空间中,使得相似的单词在向量空间中距离较近。
我们的目标是将大模型跟私域知识做匹配,因此我们需要一个嵌入模型帮我们把私域知识内容传输给大模型,这里我们使用m3e-base这个嵌入模型
M3E 是 Moka Massive Mixed Embedding 的缩写
Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量
下载地址:moka-ai/m3e-base
git lfs install
git clone https://huggingface.co/moka-ai/m3e-bas上面方式如果效率很低,直接进入下载地址,切到Files and versions部分,一个一个文件点下载按钮也是一个方式

大模型能力API化
前面步骤让我们具备了大模型的能力,但我们需要把大模型的问答能力,私域知识向量化的能力API化,才能形成私域知识库与大模型的交互。
我们直接利用chatglm.cpp里带的chatglm_cpp/openai_api.py改动下,改成该内容,启动本地的python服务,这个服务主要启动两个API服务
- /v1/chat/completions
- /v1/embeddings
上面脚本里的22行大模型文件路径和208行嵌入模型路径需要改成本地实际的路径
model: str = "/Users/chenzujie/work/Ai/chatglm.cpp/chatglm3-ggml-q8.bin";
embeddings_model = SentenceTransformer('/Users/chenzujie/work/Ai/m3e-base', device='cpu')然后我们回到chatglm.cpp的根目录,启动python服务,端口号为8000
MODEL=./chatglm3-ggml-q8.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000该命令容易遇到各种问题,比如各种第三方依赖找不到如下,我自己碰到了5 6个依赖没装,一一安装即可。
zsh: command not found: uvicorn这种依赖找不到的解决方案比较简单
pip3 install uvicorn我本地有碰到一个比较奇怪的问题是uvicorn明明已经安装好,却一直提示找不到,后来我把启动服务的命令改成如下绕过这个问题
MODEL=./chatglm3-ggml-q8.bin python3 -m uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000除了安装依赖的问题,很多人启动服务的时候都遇到了ModuleNotFoundError: No module named ‘chatglm_cpp._C’的提示导致失败。可以尝试如下方法解决
- 可以尝试把编译出来的文件 _C.cpython-311-darwin.so 放到 chatglm_cpp 目录下—-我没有找到 _C.cpython-311-darwin.so这个文件,因此用的不是这个方法
- 用 find . -name ” _C.cpython-311-darwin.so”
- https://github.com/li-plus/chatglm.cpp/issues/91 cd到其他目录(比如chatglm_cpp)编译,对应的命令启动服务命令也要去修改MODEL=../chatglm3-ggml-q8.bin python3 -m uvicorn openai_api:app –host 127.0.0.1 –port 8000,该新命令修改了MODEL和openai_api的路径
执行成功后我们会在命令行看到服务启动成功的信息

搭建知识库应用
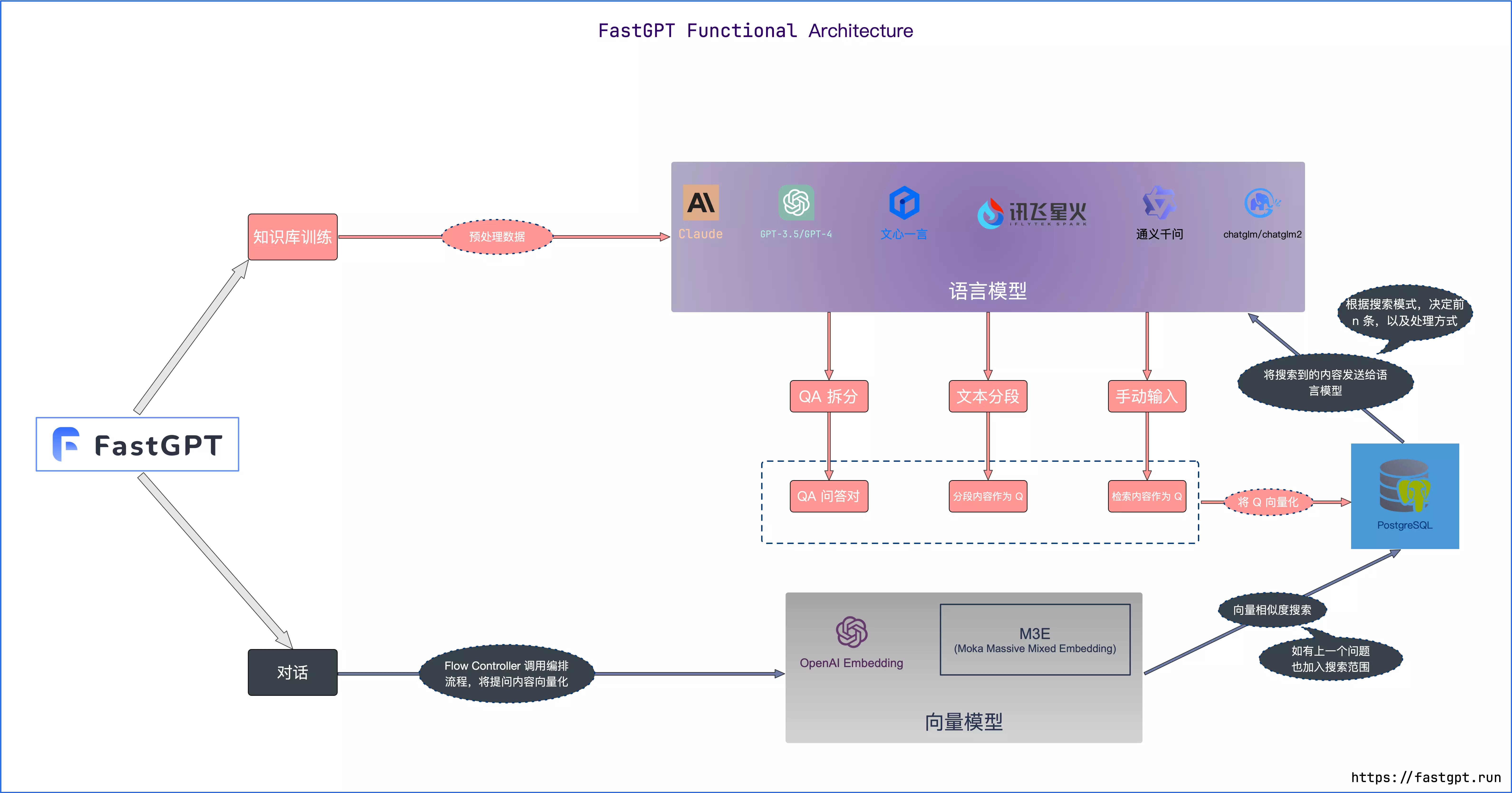
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
上面这段话是从FastGPT官网摘抄出来的,简单理解,FastGPT就是一个可视化聚合大模型跟嵌入模型的在线工具,具体流程可以看下图。
MongoDB安装
FastGPT 基于 MongoDB 存储知识库索引、会话内容、工作流等管理数据
- 可以通过链接下载MongoDB安装包
- 解压后重命名我MongoDB
- 把 MongoDB/bin拷贝到指定目录(比如我放在/usr/local目录下)并把路径添加到 PATH 路径中:export PATH=/路径/MongoDB/bin:$PATH
- export PATH=/usr/local/mongodb/bin:$PATH
- 新建一个存放FastGPT mongo数据的本地目录如下,主要是db,etc, logs3个目录,其中etc下面放了一个mongo启动的配置文件mongo.conf,该文件里的dbpath和logpath要换成自己的真实目录。
- 启动mongod

#数据库路径
dbpath=/Users/chenzujie/fastGPTMongodbData/mongo/db/
#日志输出文件路径
logpath=/Users/chenzujie/fastGPTMongodbData/mongo/logs/mongo.log
#错误日志采用追加模式,配置这个选项后mongodb的日志会追加到现有的日志文件,而不是从新创建一个新文件
logappend=true
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=false
#是否后台启动,有这个参数,就可以实现后台运行
fork=true
#端口号 默认为27017
port=27017启动命令:sudo mongod -f /Users/chenzujie/fastGPTMongodbData/mongo/etc/mongo.conf上面启动命令的mongo.conf要换成自己电脑的真实目录
PostgreSQL & pgvector安装
PostgreSQL 的官网下载 PostgreSQL 安装包:https://www.postgresql.org/download/macosx/
安装完成后登录postgre
#以postgres用户登录
sudo -u postgres /Library/PostgreSQL/16/bin/psql
#进入到PostgreSQL命令行
#新建数据库fastgpt
postgres=CREATE DATABASE fastgpt;pgvector安装:https://github.com/pgvector/pgvector
git clone --branch v0.5.1 https://github.com/pgvector/pgvector.git
// 安装 pgvector 前指定 PostgreSQL 位置
export PG_CONFIG=/Library/PostgreSQL/16/bin/pg_config
cd pgvector
make OPTFLAGS=""
make install # may need sudo在make的时候可能会遇到如下错误
clang: warning: no such sysroot directory: '/Library/Developer/CommandLineTools/SDKs/MacOSX11.3.sdk' [-Wmissing-sysroot]
clang: warning: no such sysroot directory: '/Library/Developer/CommandLineTools/SDKs/MacOSX11.3.sdk' [-Wmissing-sysroot]
clang: error: the clang compiler does not support '-march=native'可以通过新增软连接的方式解决
sudo ln -s /Library/Developer/CommandLineTools/SDKs/MacOSX13.sdk /Library/Developer/CommandLineTools/SDKs/MacOSX11.3.sdk有的人会提示no such sysroot directory: ‘/Library/Developer/CommandLineTools/SDKs/MacOSX11.sdk,
改法也是一样新增软连接,只是新增命令的最后一个参数改成/Library/Developer/CommandLineTools/SDKs/MacOSX11.sdk即可
有时候会遇到提示找不到pg_config
make: ls-pg_config: Command not found
make: *** No rule to make target `install'. Stop.可以修改下make install命令可以解决该问题
export PG_CONFIG=/Library/PostgreSQL/16/bin/pg_config
sudo --preserve-env=PG_CONFIG make install安装完成之后确认下插件是否安装到PostgreSQL目录下
// 确保插件已安装到 PostgreSQL 目录下
cd /Library/PostgreSQL/16/share/postgresql/extension/
ls | grep vector有信息输出代表插件已经安装到对应目录下

同时我们要回到PostgreSQL的命令行新建一个extennsions
#以postgres用户登录
sudo -u postgres /Library/PostgreSQL/16/bin/psql -d fastgpt
#进入到PostgreSQL命令行
#建立新的扩展
postgres=PostgreSQL create extensions;
#查询是否建立成功
postgres=SELECT * FROM pg_extension WHERE extname = 'vector';出现下图信息证明extennsions安装成功

FastGPT搭建
git clone git@github.com:labring/FastGPT.git- 将projects/app里的.env.template改成.env.local,内容改成如下格式
# 默认用户密码,用户名为 root,每次重启时会自动更新。
DEFAULT_ROOT_PSW=123456
# 数据库最大连接数
DB_MAX_LINK=5
# token
TOKEN_KEY=dfdasfdas
# 文件阅读时的秘钥
FILE_TOKEN_KEY=filetokenkey
# root key, 最高权限
ROOT_KEY=fdafasd
# openai 基本地址,可用作中转。
# OPENAI_BASE_URL=https://api.openai.com/v1
# oneapi 地址,可以使用 oneapi 来实现多模型接入
ONEAPI_URL=http://127.0.0.1:8000/v1
# 通用key。可以是 openai 的也可以是 oneapi 的。
# 此处逻辑:优先走 ONEAPI_URL,如果填写了 ONEAPI_URL,key 也需要是 ONEAPI 的 key
CHAT_API_KEY=sk-xxxx
# mongo 数据库连接参数
# MONGODB_URI=mongodb://username:password@0.0.0.0:27017/fastgpt?authSource=admin
MONGODB_URI=mongodb://127.0.0.1:27017/fastgpt?authSource=admin
# PG 数据库连接参数
# PG_URL=postgresql://username:password@host:port/postgres
PG_URL=postgresql://postgres:@localhost:5432/fastgpt
# 首页路径
HOME_URL=/其中主要是修改ONEAPI_URL为之前启动的大模型服务地址http://127.0.0.1:8000/v1
MongoDB和PostgreSQL也要修改对应的访问地址
MongoDB访问地址为mongodb://127.0.0.1:27017/fastgpt?authSource=admin
PostgreSQL访问地址为postgresql://postgres:@localhost:5432/fastgpt,这里要注意用户名跟密码要跟本机配的所匹配
- 在 config.local.json 里面注册大数据模型和向量嵌入模型,修改对应的ChatModels和VectorModels
"ChatModels": [
{
"model": "ChatGLM3",
"name": "ChatGLM3",
"price": 0,
"maxContext": 16000,
"maxResponse": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
}
],
"VectorModels": [
{
"model": "m3e-base",
"name": "m3e-base",
"price": 0,
"defaultToken": 700,
"maxToken": 3000
}
],- 安装 Node.js 依赖并以开发模式启动
# 代码根目录下执行,会安装根 package、projects 和 packages 内所有依赖
pnpm i
# 切换到应用目录
cd projects/app
# 开发模式运行
pnpm dev启动成功后打开http://127.0.0.1:3000/ 就可以看到FastGPT启动成功了。
私域知识验证
经过前面的步骤,终于到了私域知识的验证这步了,登录FastGPT,默认用户名root,密码123456。
参考快速上手新建一个知识库和应用
其中新建知识库的时候索引模型选择m3e-base


比如这里我把自己之前的一篇博客内容录入。
创建应用的时候选择知识库+对话引导类型


最后记住保存并预览。
最后的最后就可以愉快得问私域问题并看看回答效果了!!